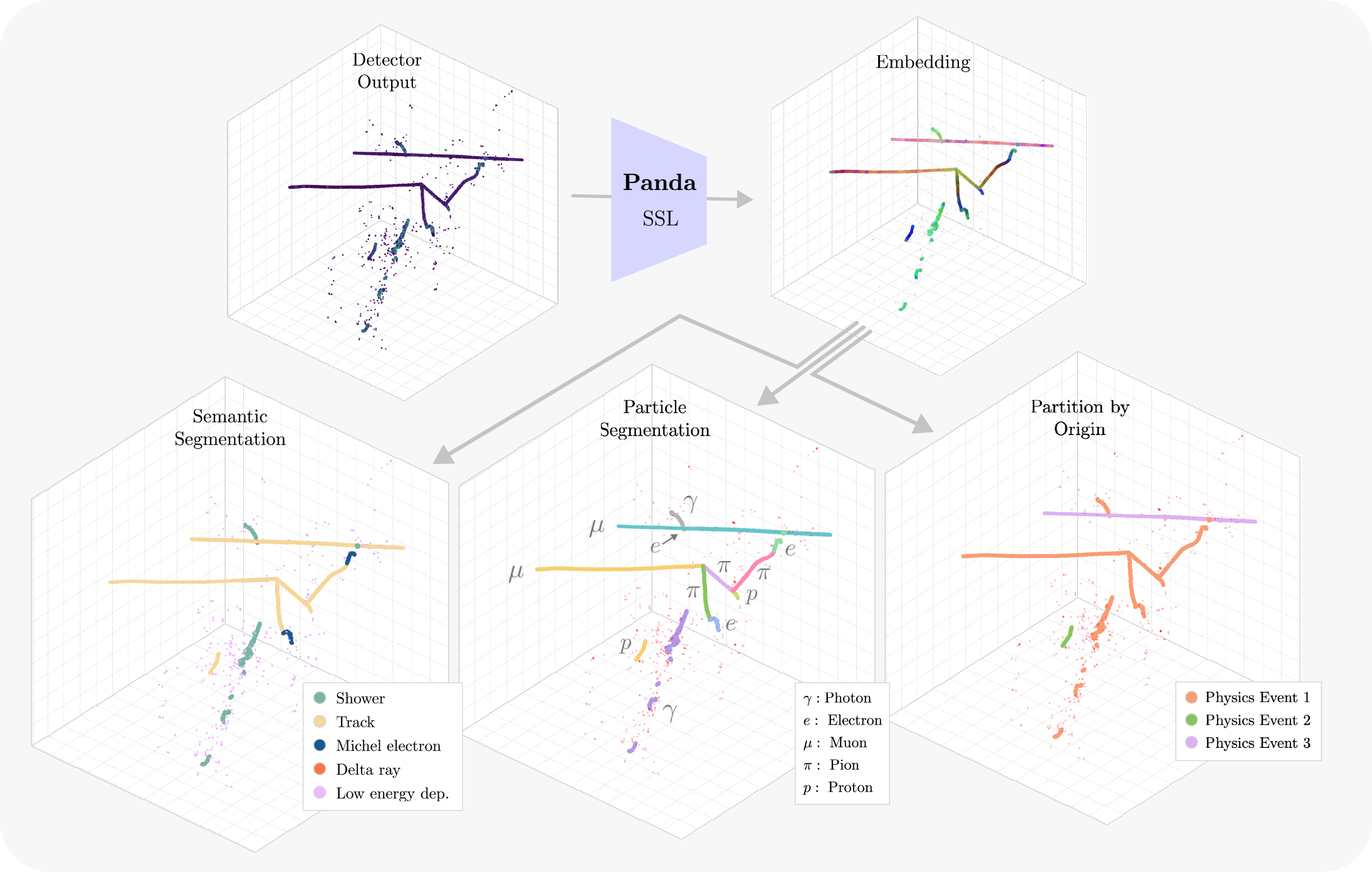
Liquid argon time projection chambers (LArTPCs) provide dense, high-fidelity 3D measurements of particle interactions and underpin current and future neutrino and rare-event experiments. Physics reconstruction typically relies on complex detector-specific pipelines that use tens of hand-engineered pattern recognition algorithms or cascades of task-specific neural networks that require extensive, labeled simulation.
We introduce Panda, a model that learns reusable sensor-level representations directly from raw unlabeled LArTPC data. Panda couples a hierarchical sparse 3D encoder with a multi-view, prototype-based self-distillation objective. On a simulated dataset, Panda substantially improves label efficiency and reconstruction quality, beating the previous state-of-the-art semantic segmentation model with 1,000× fewer labels. We also show that a single set-prediction head 1/20th the size of the backbone with no physical priors trained on frozen outputs from Panda can result in particle identification that is comparable with state-of-the-art reconstruction tools.
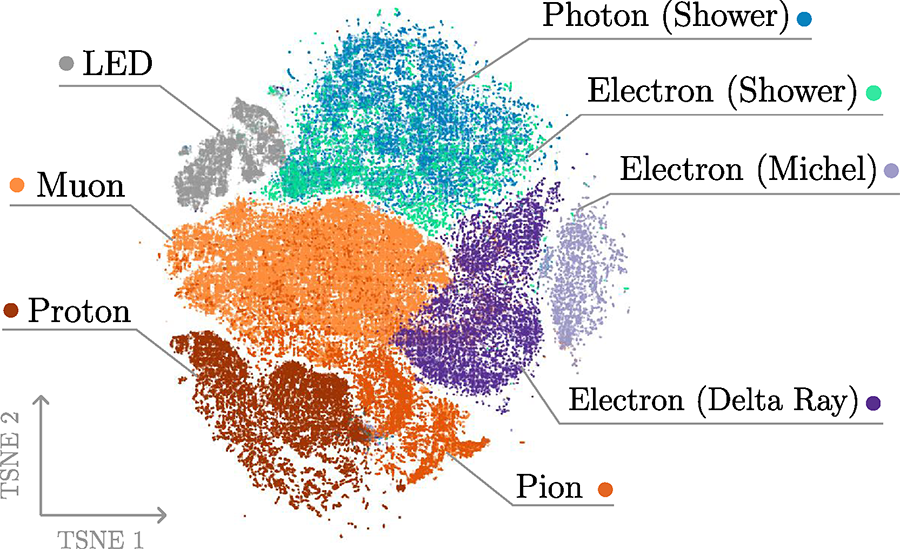
The outputs of the backbone, cast to 2D using t-SNE, capture both inter-class diversity and intra-class multi-modality. For example, electrons manifest as showers, Michel electrons, or Delta rays, and the model learns to separate these naturally.
Some overlap between photon/electron and muon/pion clusters reflects genuine physical ambiguities in LArTPC data. For example, photon- and electron-initiated electromagnetic showers can be indistinguishable should there be no resolvable conversion gap and unreliable energy deposition patterns.
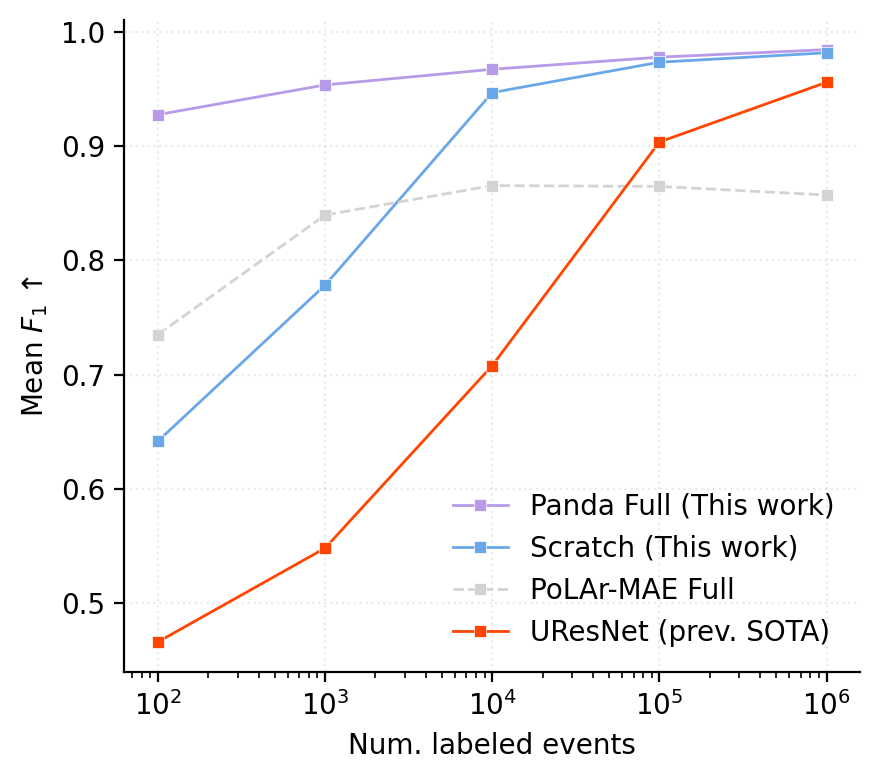
Full fine-tuning for the semantic segmentation task using just 1,000 events matches the previous SOTA trained on 1M labels. Pre-training greatly outperforms the previous SSL method, PoLAr-MAE, by a large margin at all label counts.

@misc{young2025pandaselfdistillationreusablesensorlevel,
title={Panda: Self-distillation of Reusable Sensor-level Representations for High Energy Physics},
author={Samuel Young and Kazuhiro Terao},
year={2025},
eprint={2512.01324},
archivePrefix={arXiv},
primaryClass={hep-ex},
url={https://arxiv.org/abs/2512.01324},
}